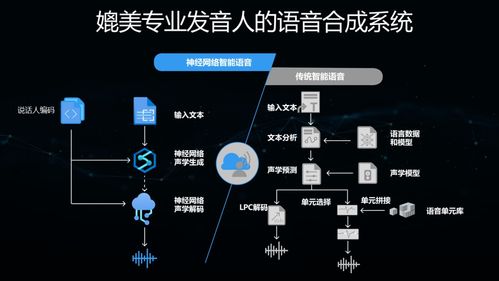
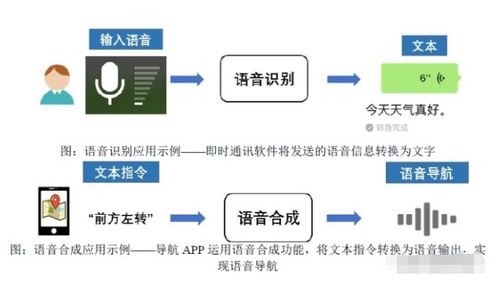
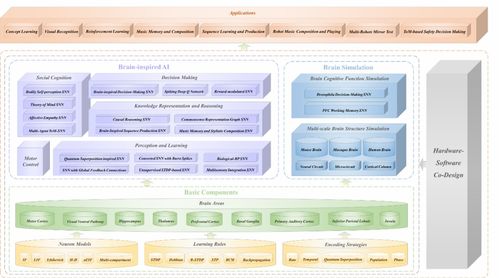
圖文識別訓練與跨模態(tài)預訓練 人工智能基礎軟件開發(fā)新篇章
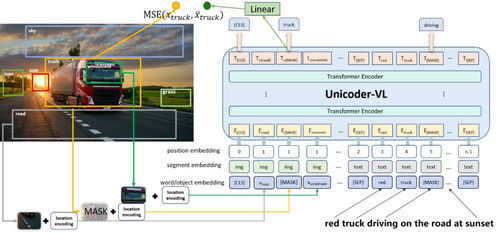
隨著人工智能技術的快速發(fā)展,圖文識別訓練與機器推理已成為推動行業(yè)進步的重要驅動力。在機器推理系列第五彈中,文本與視覺的融合成為焦點,跨模態(tài)預訓練技術正展現(xiàn)出前所未有的潛力,為人工智能基礎軟件開發(fā)帶來新的機遇與挑戰(zhàn)。
一、圖文識別訓練:從單模態(tài)到多模態(tài)的演進
傳統(tǒng)的圖文識別訓練主要關注單一模態(tài)的數(shù)據(jù)處理,例如文本識別或圖像識別。實際應用中,信息往往以多模態(tài)形式存在,如社交媒體中的圖片配文、視頻中的語音和字幕等。因此,研究人員開始探索跨模態(tài)訓練方法,通過融合文本與視覺數(shù)據(jù),提升模型的綜合理解能力。例如,基于深度學習的模型能夠同時分析圖像中的物體和文本描述,實現(xiàn)更精準的場景識別與內(nèi)容生成。
二、機器推理系列第五彈:文本與視覺的深度融合
在機器推理系列的最新進展中,文本與視覺的跨模態(tài)預訓練成為關鍵突破點。通過大規(guī)模多模態(tài)數(shù)據(jù)集(如圖文對、視頻文本對)的訓練,模型能夠學習文本與視覺之間的語義關聯(lián),從而在推理任務中表現(xiàn)出色。例如,在視覺問答(VQA)任務中,模型不僅需要識別圖像中的內(nèi)容,還需理解問題文本的意圖,給出準確的答案。跨模態(tài)預訓練技術通過自監(jiān)督學習,讓模型在無標簽數(shù)據(jù)中自動發(fā)現(xiàn)模態(tài)間的內(nèi)在聯(lián)系,大大提升了泛化能力。
三、跨模態(tài)預訓練新進展:技術突破與應用前景
跨模態(tài)預訓練技術取得了顯著進展。一方面,模型架構不斷優(yōu)化,如Transformer-based模型(如ViT、BERT)的擴展,使得文本與視覺特征的融合更加高效。另一方面,預訓練策略的創(chuàng)新,如對比學習、掩碼建模等,增強了模型對多模態(tài)數(shù)據(jù)的理解能力。這些進展不僅推動了學術研究,還為實際應用奠定了基礎,例如智能客服中的圖文交互、自動駕駛中的環(huán)境感知等。
四、人工智能基礎軟件開發(fā)的機遇與挑戰(zhàn)
跨模態(tài)預訓練技術的興起,為人工智能基礎軟件開發(fā)帶來了新機遇。開發(fā)者可以利用開源預訓練模型(如OpenAI的CLIP、谷歌的ViLBERT)快速構建多模態(tài)應用,降低開發(fā)門檻。軟件工具鏈的完善,如PyTorch、TensorFlow對多模態(tài)訓練的支持,進一步加速了創(chuàng)新進程。挑戰(zhàn)也隨之而來:數(shù)據(jù)隱私與安全、模型可解釋性、計算資源需求等問題仍需深入解決。隨著技術的成熟,人工智能基礎軟件將更注重易用性、可擴展性和倫理合規(guī)性。
圖文識別訓練與跨模態(tài)預訓練正在重塑人工智能領域。通過文本與視覺的深度融合,機器推理能力不斷提升,為人工智能基礎軟件開發(fā)注入了新活力。隨著技術的不斷突破,我們有望看到更加智能、高效的多模態(tài)應用,推動社會邁向更智慧的時代。
如若轉載,請注明出處:http://www.hualeqipai.cn/product/62.html
更新時間:2026-02-14 10:40:42